
Via een tweet van Peter De Bruyn (van zelfstandigen.be) op de SEO-fail van de dag uitgekomen bij “digitaal mediabureau” Truvo (beter gekend als de mannen van de Gouden gids).
Is dit niet vreemd voor een bedrijf dat zegt digitale oplossingen aan te bieden? pic.twitter.com/xrRx1bx2vR
— Peter De Bruyn (@debruynpeter) January 8, 2014
Als je op Truvo zoekt in google zie je volgende onheilspellende tekst verschijnen als omschrijving:
“Er is geen beschrijving beschikbaar voor dit resultaat vanwege robots.txt – meer informatie.”
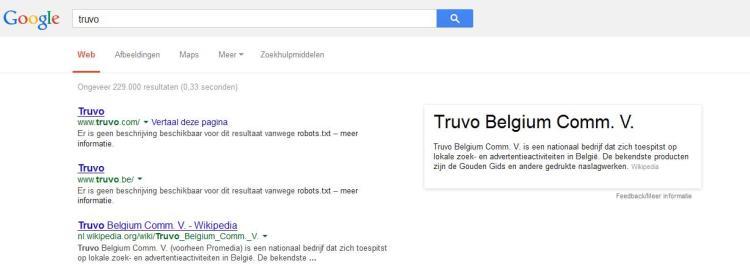
Het gevaar van de robots.txt
Via het kleine technische SEO bestandje robots.txt (zie informatie google hierover) kan je aan de vele duizenden automatische spiders/bots op het net instructies gaan meegeven. Zo kan je zoals newsmonkey.be tegen alle bots gaan zeggen, dat ze vooral NIET pagina “/Pn3w344g912t6O1” mogen bezoeken en opnemen in bijvoorbeeld de google-resultaten. Nu heb je ineens die private beta indexpagina link voor de newsmonkey investeerders.
Truvo is dus nog een stapje verder gegaan en heeft nu aan alle bots aangegeven, dat ze hun pagina’s niet mogen doorzoeken/opnemen in de google resultaten. OK dan…
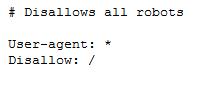
Je kan maar hopen dat ze dit niet doen bij al die duurbetaalde truvo-websites voor de plaatselijke bakkers, schrijnwerkers,…
Het controleren en opzetten van een correcte robots.txt is een standaard stap in mijn SEO audit van een website.
Robots.txt weetjes
Het veranderen van een dergelijke foutieve robots.txt kan trouwens heel enkele dagen duren, omdat je aan google hebt verteld die website niet meer te bezoeken.
How long will it take for changes in my robots.txt file to affect my search results?
First, the cache of the robots.txt file must be refreshed (we generally cache the contents for up to one day). Even after finding the change, crawling and indexing is a complicated process that can sometimes take quite some time for individual URLs, so it’s impossible to give an exact timeline. Also, keep in mind that even if your robots.txt file is disallowing access to a URL, that URL may remain visible in search results despite that fact that we can’t crawl it. If you wish to expedite removal of the pages you’ve blocked from Google, please submit a removal request via Google Webmaster Tools.
Via de google webmastertools kan je best via de fetch-optie je robots.txt veldje terug manueel aanbieden.
Ams de google bot je robots.txt trouwens niet kan lezen, dan stopt hij ook met het doorzoeken van je volledige website.
Nog een leuk robots.txt truukje geleerd van Henk Van Ess is om met bijvoorbeeld followthatpage.com de robots.txt van google te gaan volgen. Zo ben je als eerste op de hoogte als ze weer een nieuwe feature/toepassing op de google website plaatsen.

Als het daadwerkelijke een reden heeft om die truvo.be/truvo.com domeinnamen uit google te houden, zijn er betere oplossingen.
We hebben uiteraard met een reden truvo.be en truvo.com tijdelijk geblokkeerd voor zoekmachines. Er was namelijk een issue met een bedrijf dat dezelfde merknaam heeft. Dit wordt zo snel mogelijk uitgeklaard en dan kunnen we de robots.txt aanpassen.
Uiteraard zijn de MySites van onze klanten niet geblokkeerd. Meer dan 23.000 gecrawlde MySites en 8 miljoen bezoekers per maand zijn daar een bewijs van.
Met dank aan followthatpage.com deze morgen gezien dat ze hun robots.txt aangepast hebben:
http://www.truvo.com/robots.txt
Bij Newsmonkey staat ie blijkbaar ook op dissalow: / ? Of zijn ze nog niet officieel gelanceerd?
Ja inderdaad. ZIe:
https://twitter.com/kodel/status/423360275438243840
Enja ook hier is het een seo-foutje, dat ze dringend gaan oplossen… 😉