
Update 23 maart 2022
De brandweer heeft zijn rapport uitgebracht… Autch…
Wie de techwereld wat volgt heeft gisteren zeker stilgestaan bij een brand in een doodnormaal industrieterrein in Straatsburg, die voor vele bedrijven best grote gevolgen heeft.
Het was deze tweet die me woensdagochtend ook direct wakker schudde:
We have a major incident on SBG2. The fire declared in the building. Firefighters were immediately on the scene but could not control the fire in SBG2. The whole site has been isolated which impacts all services in SGB1-4. We recommend to activate your Disaster Recovery Plan.
— Octave Klaba (@olesovhcom) March 10, 2021
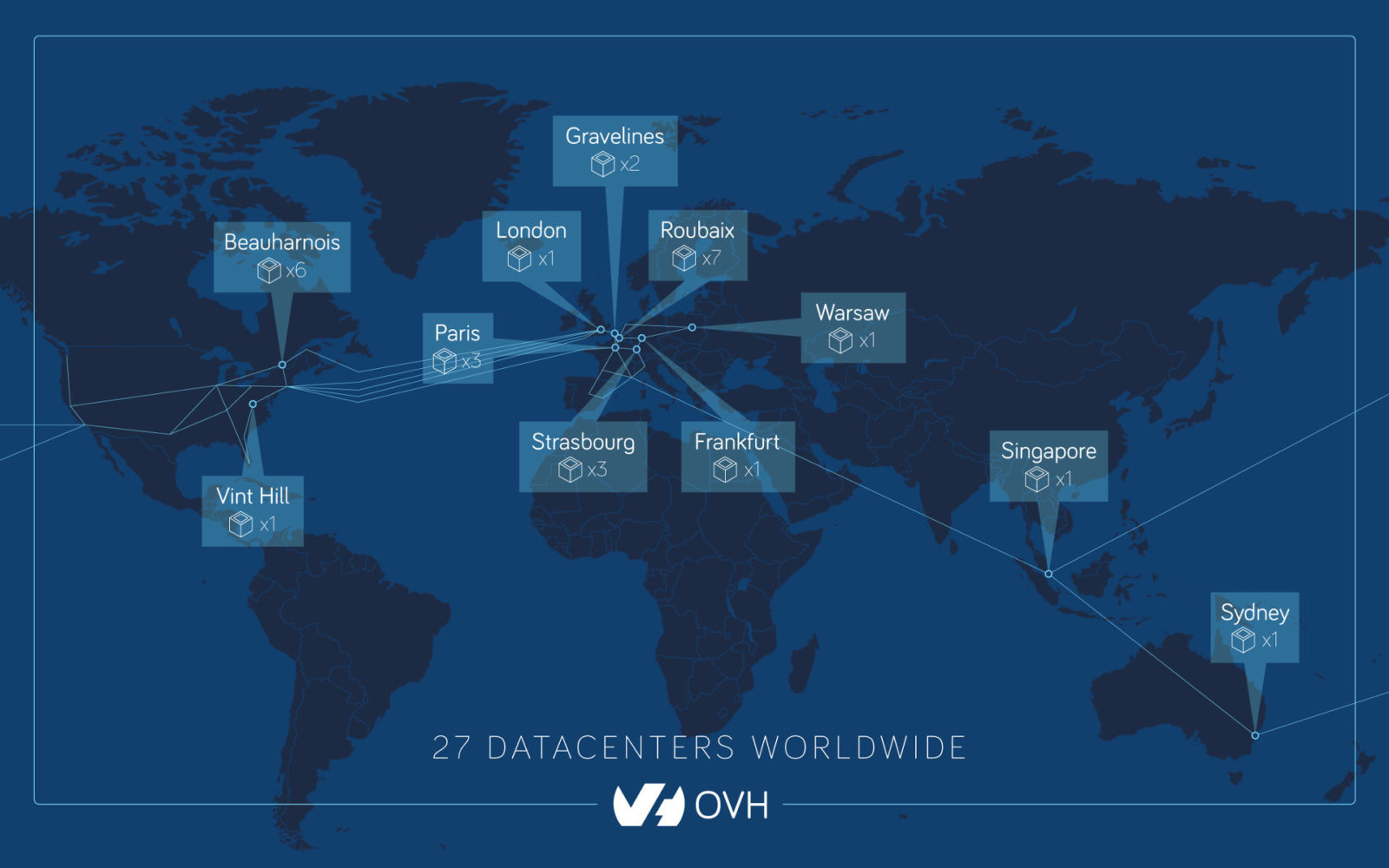
Wat je hier leest is de oprichter van de Franse Cloudspeler OVH (met 27 datacenters wereldwijd), die aangeeft dat er een brand is uitgebroken in hun SBG2 datacenter in Straatsburg (waar ze 4 datacenters hebben op dezelfde site).
Je wenst dit echt niemand toe kan ik je verzekeren en ik hoop dat ze snel de 3 andere datacenters terug up and running krijgen (ze zeggen nu 15 maart), want SBG2 is volledig verloren (30.000 servers).
Wat is de impact van een datacenter dat wegvalt?
Zoals je in mijn blogpost van eind 2019 (over het Interxion datacenter in Zaventem waar mijn website op een Combell cloudserver draait) kon lezen is een datacenter als cruciale infrastructuur opgebouwd om steeds rekening te houden met een als-als-als scenario. Redundantie is hierbij het toverwoord en dit wordt tot het uiterste doorgedreven. Denk dus in stroomtoevoer, fiber connectiekabels, blussystemen,… tot grote redundante dieselgenerators (die continu warm in standby klaarstaan).


Bij een brand gaat Argon gas de lucht wegnemen bijvoorbeeld, dus de kans dat Interxion dit meemaakt is toch weer veel kleiner.
Maar natuurlijk is er altijd die hele hele hele kleine minieme kans, dat het volledig fout gaat (en dan gaat het ook echt goed mis). Bekende verhalen zijn 9/11 waar in de WTC centers ook enkele kleinere datacenters waren en vooral de orkaanoverstroming van Manhattan in 2012 met heroïsche datacenterverhalen.
Een Disaster Recovery Plan of DRP?
In de IT wereld is risico inschatting steeds belangrijk en ga je je plannen maken op het risico en de mogelijke impact van een vooral. Dit goed uitwerken (en ook het regelmatig testen hiervan) is een zogenaamd DRP. Op welke manier kan je zo snel mogelijk terug naar “business as usual” bij een uitzonderlijke gebeurtenis en hoe ga je dit ook echt testen?
Zoals je hierboven in de tweet kan lezen, gaf Octave dus ook direct aan “We recommend to activate your Disaster Recovery plan“.
OVH is gekend als grote Europese cloudspeler (naast de gekende 3 grote internationale jongens AWS, Azure en Google Cloud) met dus datacenters in verschillende regio’s, maar met vooral 13 datacenters in Frankrijk.

We gooien alles in de cloud en klaar…
De cloud is daarbij een gegeven, waar meer en meer bedrijven hun on-premise servers naartoe migreren (on-premise zijn servers in je eigen serverkot in de kelder van je bedrijf bijvoorbeeld). Daarbij wordt er dan vanuit gegaan, dat de cloud onfeilbaar is (Zelfs AWS toont dit om de zoveel jaar altijd wel eens).
Een migratie naar de cloud brengt inderdaad al een eerste stap, waarbij je het risico van een eigen serverhok (met dus een grote kans op problemen) al gaat oplossen. Maar je verschuift een eventueel risico ook naar een ander niveau.
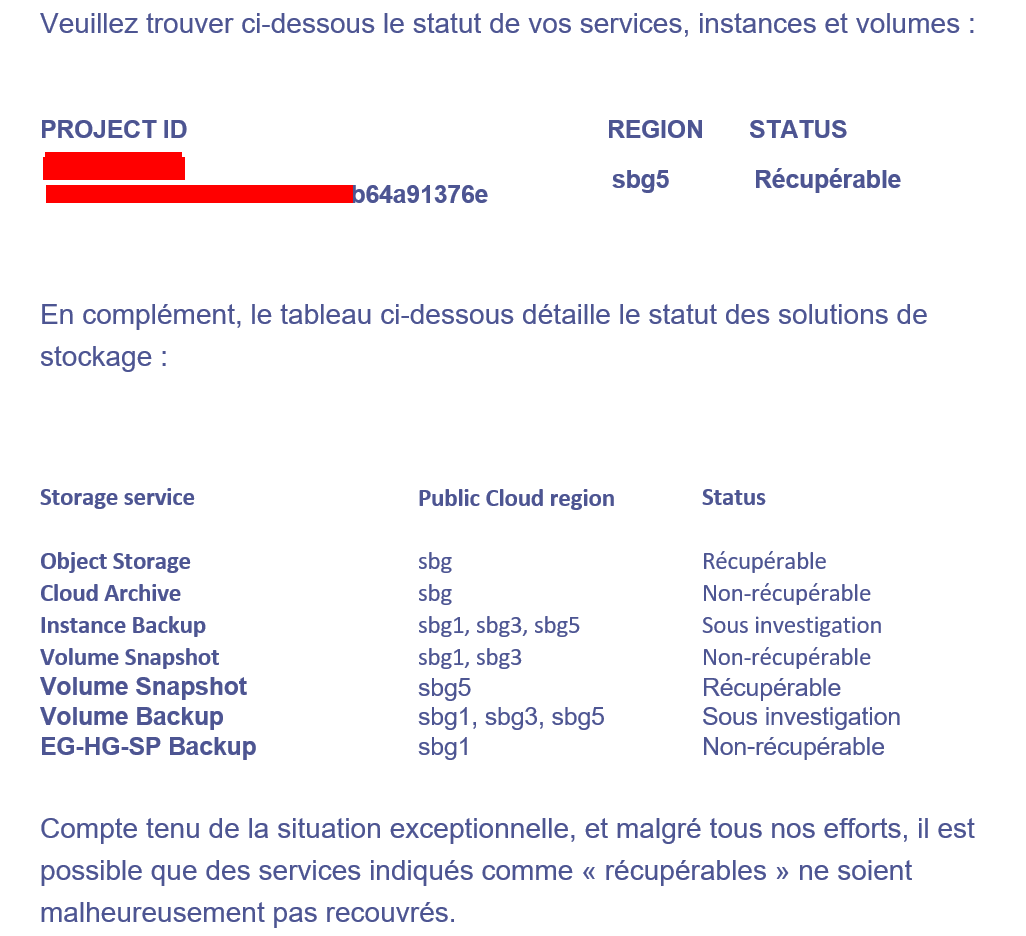
Dit is de mail die getroffen klanten nu krijgen over hun data en hun backups…

Het als-als-als scenario in de praktijk?
Maar hoe moet je dan gaan denken in een DRP? Je gaat hierbij uit van hoe snel kan je terug operationeel zijn met al je processen. 1 jaar geleden kwamen we er bijvoorbeeld massaal achter dat er weinig DRP-plannen rekening hadden gehouden met een pandemie, waarbij ALLE werknemers plots van thuis diende te gaan werken.
Ik zal een huis-keuken-tuin voorbeeld geven vanuit mijn Dailybits homeoffice met de 3-2-1 backup methode: 3 kopies van mijn data, op 2 verschillende media en met 1 off-site backup.


1. Wij hebben hier in huis 3 Apple computers, die dagelijks gebruikt worden. Wat als hier iets mee zou gebeuren?
Apple Timemachine maakt een dagelijkse kopie naar mijn Synology NAS van deze 3 Apple computers (die nu mooi in een serverrack staat). Gaat er 1 van die computers kapot, dan kunnen we een Timemachine backup zo terugzetten op een nieuw exemplaar. We hebben hier zelfs een Chromebook liggen, waardoor we altijd wel online kunnen.
2. Wat als mijn Synology NAS 1 van zijn harde schijven zou crashen?
De 2 harde schrijven in de NAS staan in Raid 1, wat betekent dat als er 1 harde schijf crashed, dan is er nog niets verloren, want alles staat in mirror op de 2 harde schijven. Nieuwe schijf bestellen, erbij duwen en alles terug laten synchroniseren.
3. Wat als mijn Synology NAS 2 van zijn harde schijven zouden crashen?
Paniek… Gelukkig wordt elk weekend een encrypted backup weggeschreven naar Amazon Glacier in Ierland (Cold-storage = goedkoop om te uploaden naar daar, maar duur om eventueel in noodgeval terug te moeten halen). Die staan zelfs zo goed daar, dat het verwijderen van die backups een hele uitdaging was.
Weetje: In 2013 was mijn Telenet verbinding nog niet goed genoeg voor zulke grote cloudbackups, dus had ik offline backups in huis in een brandwerende box. 🔥
Hoe zit dit dan met deze website?
Ikzelf heb het met Dailybits dus al meegemaakt, dat ik al mijn websites kwijt was (in 2004 door ongeval zaakvoerder van het eenmansbedrijf waar mijn blog stond, ik kwam erachter toen alles plots weg was 🙈).
Dus ik ben me daar nu echt bewust van en denk dus ook altijd aan de verschillende risico’s:
- Deze website draait op een Combell VMWare cloudserver bij Interxion in Zaventem, die gemanaged wordt door hen en waar ik een goede SLA op heb.
- Backup van de server wordt standaard bij hen in een ander datacenter gestockeerd (LCL in Diegem in dit geval). Deze service bieden ze trouwens ook aan voor cloud backup van je on-premise servers.
- Zelf gebruik ik daarnaast ook Managewp wat van Dailybits.be elke dag een WordPress backup bij hen in de cloud maakt.
- Op mijn computer heb ik ook nog een jaarlijkse backup van vooral de configuratie en themefiles.
Hoe zit dat nu met spreiden over meerdere datacenters?
Het volledig verliezen van een datacenter is iets, wat maar zeer zelden voorkomt (gelukkig maar).
Maar een bedrijf met kritische applicaties zal in zijn DRP steeds rekening houden met deze mogelijkheid. In mijn SQL Server Admin periode midden jaren 2000 heb ik als consultant nog de replicatiefeature van een groot nationaal bedrijf zijn MSSQL databaseservers opgezet. Elke maand werd dit ook mooi getest, waarbij alles binnen de minuut van datacenter wisselde (alles werd continu in sync gehouden over 2 datacenters met 1 die in productie was en de andere in standby stond). We spreken hier over 15 jaar geleden dus…
Je ziet dan ook zeker bij veel grote bedrijven een multi-datacenter opkomen, waarbij alle data en applicaties over verschillende datacenters worden gesynchroniseerd.
Enja ook in het OVH verhaal, zag je direct sysadmins voorbijkomen, die succesvol hun DRP hadden kunnen uitvoeren.
Good luck Octave. I feel for you. One of our (many) servers is in SBG-3, but we failed over to our backup in LIM (we keep offsite backups & have a disaster recovery plan – which came through tonight). OVH has served us well, and I know you will be back at full strength + soon!
— Murray G. (@mgetc) March 10, 2021
Moraal van het verhaal?
Moraal van het verhaal (en ik merkte het duidelijk aan enkele mailtjes van klanten): maak op voorhand je plan en weet waar je data zit (enja een budget datacenter gaat soms wat meer risico nemen), waar je backups staan (staan ze in hetzelfde gebouw?), wat de kwaliteit van deze datacenters is,… Ook voor je GDPR verwerkingsregister heb je deze info nodig trouwens.
Denk aan alle risico’s (remember deze telewerksituatie die niemand ooit had voorzien) en ga je hierop voorzien. Je servers naar de cloud migreren is niet genoeg, als je backups 1 meter verder op een server staan te staan.



Nog een tip! Gebruik geen backup datacenter zoals bijvoorbeeld SBG1 die dus letterlijk maar enkele meters verwijderd is van SBG2. 😉
Klopt. Ik heb een tweakers thread gezien met foto’s van die dc’s en laat ons stellen dat ik ervan verschoot… https://tweakers.net/nieuws/179030/brand-verwoest-datacenter-van-franse-provider-ovhcloud.html
Die dc SBG1 zijn dus inderdaad die zeecontainers, die nu ook wel wat schade gaan hebben vermoedelijk…
Even ter documentatie, deze super thread over SEO zaken die je kan doen bij zulke outages. https://twitter.com/johnmu/status/1369939925064355841